Introduction
Machine Learning (ML) is a fascinating field that empowers computers to learn from data and make intelligent decisions. In this article, we’ll walk through the essential steps of a machine learning project using Python, along with sample code snippets.
Step 1: Define the Problem
- Before diving into code, clearly define the problem you want to solve. Whether it’s classification, regression, or clustering, a well-defined problem guides the entire machine learning process.
Step 2: Gather and Explore Data
- Collect relevant data for your problem. Use libraries like Pandas for data manipulation and exploration. Visualize the data to gain insights using Matplotlib or Seaborn.
import pandas as pd
import matplotlib.pyplot as plt
# Load data
data = pd.read_csv('your_dataset.csv')
# Explore data
print(data.head())
plt.scatter(data['feature1'], data['feature2'])
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
Step 3: Preprocess Data
- Clean the data by handling missing values, encoding categorical variables, and scaling numerical features. Scikit-learn provides useful tools for preprocessing.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Separate features and target variable
X = data.drop('target', axis=1)
y = data['target']
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
Step 4: Choose a Model
- Select a suitable machine learning model based on your problem. Scikit-learn offers a variety of models for different tasks.
from sklearn.ensemble import RandomForestClassifier # Choose a model model = RandomForestClassifier() # Train the model model.fit(X_train_scaled, y_train)
Step 5: Evaluate the Model
- Assess your model’s performance using appropriate metrics. For classification, you might use accuracy, precision, recall, or F1-score.
from sklearn.metrics import accuracy_score, classification_report
# Make predictions
y_pred = model.predict(X_test_scaled)
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print(f'Classification Report:\n{report}')
Step 6: Fine-Tune the Model
- Fine-tune your model by adjusting hyperparameters or using techniques like cross-validation. GridSearchCV in scikit-learn can help automate this process.
from sklearn.model_selection import GridSearchCV
# Define hyperparameters to tune
param_grid = {'n_estimators': [50, 100, 200], 'max_depth': [None, 10, 20]}
# Perform Grid Search
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X_train_scaled, y_train)
# Get the best model
best_model = grid_search.best_estimator_
Step 7: Make Predictions
- Once satisfied with your model, use it to make predictions on new, unseen data.
# New data new_data = pd.DataFrame(...) # Create a DataFrame with your new data # Preprocess the new data new_data_scaled = scaler.transform(new_data) # Make predictions predictions = best_model.predict(new_data_scaled)
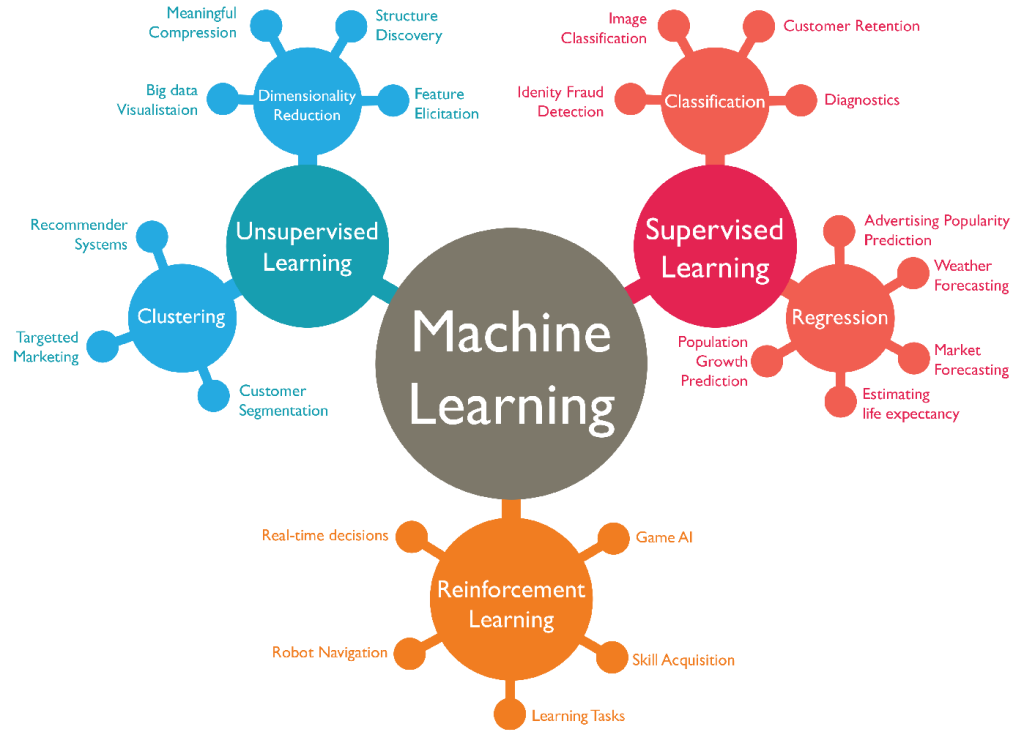
Congratulations! You’ve now completed a basic machine learning project using Python. This step-by-step guide provides a foundation for building more complex models and exploring advanced concepts in machine learning.