MongoDB, Cassandra, and ScyllaDB are all popular databases, but they have different architectures and use cases. Here’s a brief overview of their differences:
MongoDB:
- MongoDB is a document-oriented NoSQL database, which means it stores data in flexible, JSON-like documents.
- It is known for its flexibility, scalability, and ease of use.
- MongoDB is often used for applications where a high level of flexibility in the data model is required, such as content management systems, real-time analytics, and mobile applications.
- It supports rich queries, indexing, and dynamic schema.
Cassandra:
- Cassandra is a distributed NoSQL database designed for handling large amounts of data across many commodity servers, providing high availability and fault tolerance.
- It is optimized for write-heavy workloads and offers linear scalability.
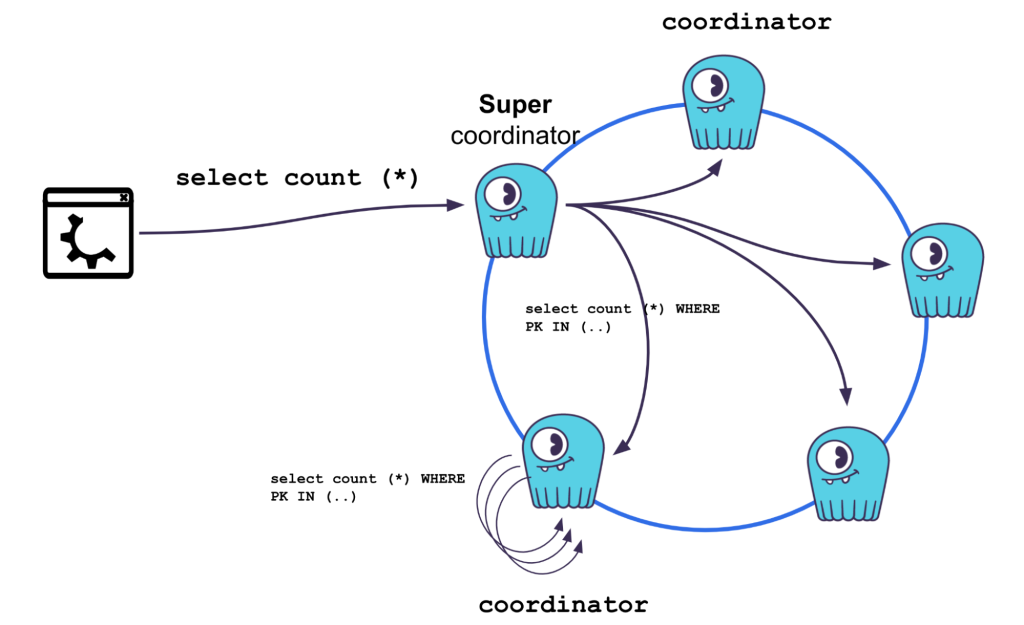
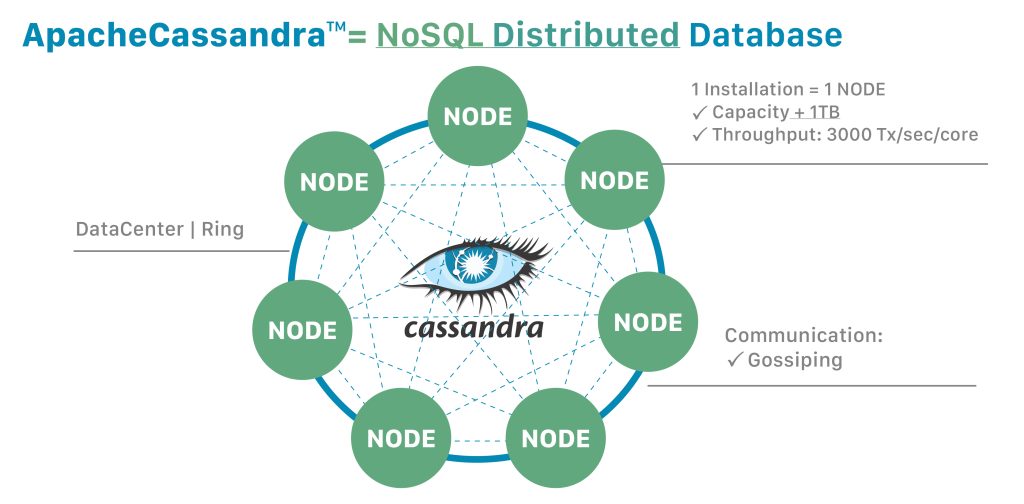
- Cassandra uses a decentralized architecture based on the principles of Amazon’s Dynamo and Google’s Bigtable.
- It is commonly used for time-series data, sensor data, messaging systems, and other applications requiring high availability and scalability.
ScyllaDB:
- ScyllaDB is a highly performant, distributed NoSQL database that is compatible with Apache Cassandra but designed to be faster and more efficient.
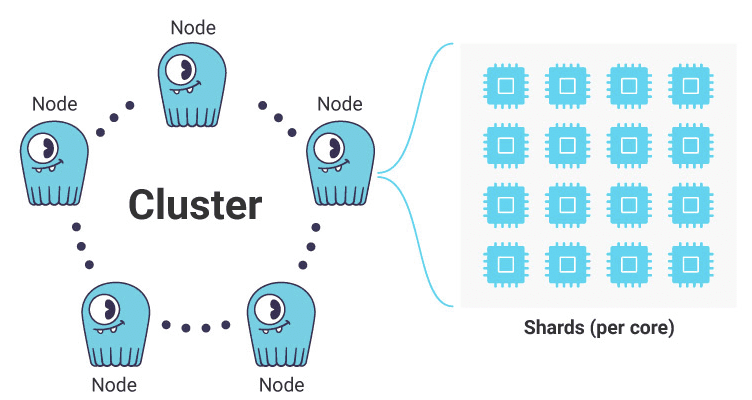
- It is built from the ground up in C++ and is optimized for modern hardware, utilizing techniques such as sharding, lock-free algorithms, and a shared-nothing architecture to achieve high throughput and low latency.
- ScyllaDB is often used in applications requiring real-time analytics, high-speed transactions, and low-latency data processing.
- It offers drop-in compatibility with existing Cassandra applications, making it easy to migrate from Cassandra to ScyllaDB.
MongoDB is a document-oriented database known for its flexibility, Cassandra is a distributed database optimized for high availability and write-heavy workloads, and ScyllaDB is a high-performance database designed to be faster and more efficient than Cassandra. The choice between them depends on the specific requirements of the application in terms of scalability, performance, and data model.
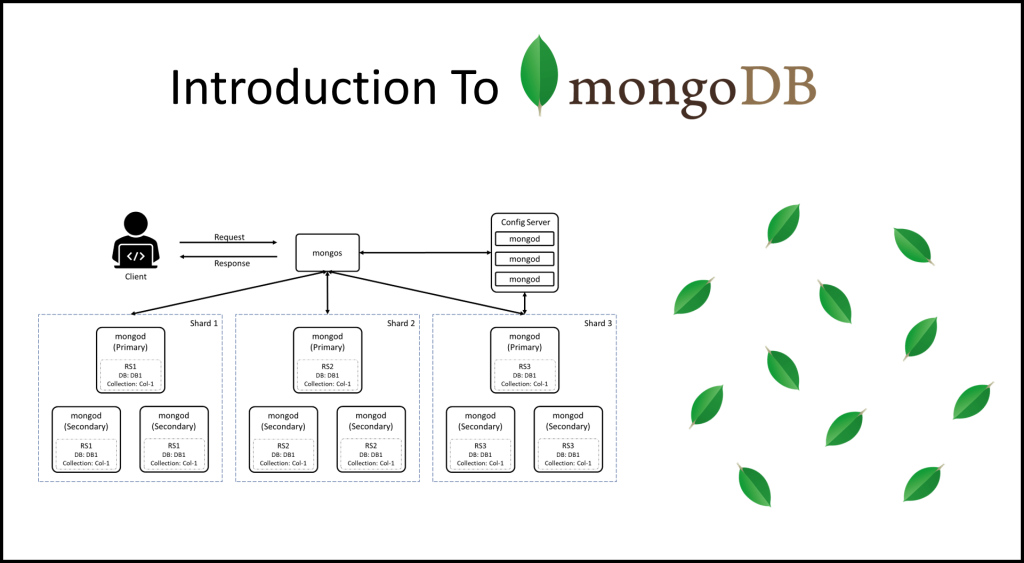
Exploring the Scalability and Flexibility of MongoDB, Cassandra, and ScyllaDB
In the ever-evolving landscape of database technologies, two critical factors often come into play: scalability and flexibility. As data volumes continue to soar and application demands become more dynamic, businesses seek database solutions that can seamlessly handle growth while accommodating diverse data structures and workloads. MongoDB, Cassandra, and ScyllaDB stand out as prominent contenders, each offering unique approaches to addressing these challenges. In this article, we delve into the scalability and flexibility of these three databases, examining their key features, architectures, and use cases.
MongoDB: Unleashing Flexibility
MongoDB has garnered significant attention for its document-oriented, NoSQL approach, making it a favorite among developers seeking flexibility in data modeling. At its core, MongoDB stores data in JSON-like documents, providing a schema-less design that empowers developers to adapt to evolving application requirements with ease. This flexibility enables rapid prototyping, iteration, and support for dynamic data structures, making MongoDB an ideal choice for projects where the schema may evolve over time.
Moreover, MongoDB’s flexibility extends to its query capabilities. With support for rich queries, indexing, and aggregation pipelines, developers can efficiently retrieve and manipulate data, even across complex nested structures. This flexibility facilitates real-time analytics, content management systems, and various other applications requiring diverse query patterns.
However, MongoDB’s approach to flexibility does introduce considerations for scalability. While MongoDB can scale horizontally through sharding, managing large-scale deployments demands careful planning and resource allocation. Additionally, the absence of strict schema enforcement may necessitate disciplined data modeling practices to prevent performance bottlenecks and ensure efficient query execution.
Cassandra: Scaling with Resilience
In contrast to MongoDB’s document-oriented paradigm, Cassandra embodies a distributed, column-family data model, purpose-built for scalability and fault tolerance. Designed to handle massive volumes of data across commodity hardware, Cassandra employs a decentralized architecture inspired by Dynamo and Bigtable, offering linear scalability and high availability.
Cassandra’s scalability stems from its distributed nature, where data is partitioned and replicated across a cluster of nodes. This design enables seamless scaling by adding or removing nodes, allowing Cassandra to accommodate growing workloads without sacrificing performance. Moreover, Cassandra’s tunable consistency levels empower developers to strike a balance between data availability and durability, catering to diverse application requirements.
Furthermore, Cassandra’s flexible data model, characterized by column families and wide rows, facilitates efficient storage and retrieval of semi-structured and time-series data. This versatility makes Cassandra well-suited for use cases such as IoT sensor data, messaging platforms, and distributed logging, where scalability and resilience are paramount.
However, Cassandra’s eventual consistency model and complex data modeling may pose challenges for developers accustomed to traditional relational databases. Achieving optimal performance often requires a deep understanding of Cassandra’s data modeling principles and cluster configuration, emphasizing the importance of careful design and tuning.
ScyllaDB: Powering Scalability with Performance
ScyllaDB emerges as a high-performance alternative to Cassandra, built from the ground up for modern hardware and demanding workloads. Compatible with Cassandra’s data model and API, ScyllaDB offers drop-in replacement capabilities while leveraging advanced optimization techniques to deliver superior throughput and latency.
At the heart of ScyllaDB lies its C++ architecture, engineered for performance and efficiency. By harnessing techniques such as sharding, lock-free algorithms, and kernel bypass networking, ScyllaDB maximizes resource utilization and minimizes overhead, enabling it to achieve near-linear scalability across multicore systems.
ScyllaDB’s emphasis on performance does not come at the expense of flexibility. Like Cassandra, ScyllaDB supports flexible data modeling and distributed data storage, enabling seamless integration with existing Cassandra applications. This compatibility, coupled with ScyllaDB’s superior performance characteristics, positions it as a compelling choice for organizations seeking to enhance scalability without sacrificing flexibility.
MongoDB, Cassandra, and ScyllaDB offer distinct approaches to addressing the twin challenges of scalability and flexibility in modern database systems. MongoDB excels in providing flexibility through its schema-less design and rich query capabilities, making it suitable for agile development and dynamic data requirements. Cassandra, on the other hand, prioritizes scalability and resilience through its distributed architecture and tunable consistency levels, catering to high-volume, distributed workloads.
Finally, ScyllaDB combines the flexibility of Cassandra’s data model with unparalleled performance, offering a compelling solution for organizations seeking to scale with speed and efficiency. Ultimately, the choice among these databases depends on the specific requirements and priorities of each project, balancing the need for flexibility, scalability, and performance.
Exploring Replica, Read-only, and Multi-Master Architectures in MongoDB, Cassandra, and ScyllaDB
Replica, read-only, and multi-master architectures play pivotal roles in shaping the scalability, availability, and performance of distributed databases. MongoDB, Cassandra, and ScyllaDB, three prominent players in the database landscape, each offer unique approaches to implementing these architectures, catering to diverse use cases and requirements. In this article, we delve into the intricacies of replica, read-only, and multi-master configurations in MongoDB, Cassandra, and ScyllaDB, exploring their key features, benefits, and considerations.
Replica Architectures: Ensuring High Availability
Replica architectures, characterized by the replication of data across multiple nodes, are essential for achieving high availability and fault tolerance in distributed databases. MongoDB, Cassandra, and ScyllaDB all offer mechanisms for implementing replica architectures, albeit with differences in their implementation details and features.
In MongoDB, replica sets serve as the foundation for ensuring data redundancy and fault tolerance. A replica set consists of multiple MongoDB instances, including a primary node responsible for processing write operations and one or more secondary nodes replicating data asynchronously from the primary. This setup enables automatic failover in the event of primary node failure, ensuring uninterrupted service and data consistency.
Cassandra employs a similar approach to replica architectures through its distributed data model and eventual consistency mechanism. Data in Cassandra is partitioned and replicated across multiple nodes, with each replica responsible for specific data partitions. By replicating data across multiple nodes within a cluster, Cassandra ensures fault tolerance and high availability, allowing for seamless read and write operations even in the presence of node failures.
ScyllaDB, being compatible with Cassandra’s data model, also embraces replica architectures to ensure data redundancy and resilience. By replicating data across multiple nodes within a ScyllaDB cluster, organizations can achieve high availability and fault tolerance, mitigating the risk of data loss and service downtime.
Read-only Architectures: Optimizing Performance and Scalability
Read-only architectures are designed to offload read operations from primary nodes to secondary nodes, thereby improving performance and scalability for read-heavy workloads. MongoDB, Cassandra, and ScyllaDB offer mechanisms for implementing read-only architectures, enabling organizations to distribute read traffic across multiple nodes efficiently.
In MongoDB, replica sets can be leveraged to support read-only operations by configuring secondary nodes as read replicas. These read replicas serve read requests independently of the primary node, reducing read latency and improving throughput for read-intensive workloads. By directing read traffic to read replicas, organizations can effectively scale read operations horizontally without impacting the performance of write operations.
Cassandra adopts a similar approach to read-only architectures through its support for multi-datacenter deployments and read/write separation. By strategically placing replica nodes in different data centers and configuring client applications to route read requests to nearby replicas, organizations can minimize read latency and optimize network bandwidth utilization. This distributed read capability enables Cassandra to scale effortlessly across geographically distributed environments while delivering consistent performance for read operations.
ScyllaDB, being designed for high performance, also offers support for read-only replicas to offload read traffic from primary nodes. By distributing read replicas across multiple nodes within a ScyllaDB cluster, organizations can achieve load balancing and scalability for read-heavy workloads, enhancing overall system performance and responsiveness.
Multi-Master Architectures: Empowering Distributed Writes
Multi-master architectures enable distributed write operations across multiple nodes, allowing organizations to achieve high write throughput and fault tolerance. While MongoDB traditionally operates in a single-master mode, both Cassandra and ScyllaDB offer support for multi-master architectures, empowering organizations to scale write operations horizontally and enhance system resilience.
Cassandra’s decentralized architecture inherently supports multi-master replication, enabling simultaneous write operations across multiple nodes within a cluster. This distributed write capability not only improves write throughput and latency but also enhances fault tolerance by ensuring that write operations can proceed independently of node failures. With multi-master replication, organizations can achieve near-linear scalability for write-intensive workloads, making Cassandra an ideal choice for high-volume, distributed applications.
Similarly, ScyllaDB embraces multi-master replication to enable distributed write operations and enhance write throughput. By supporting multiple writable replicas within a ScyllaDB cluster, organizations can distribute write traffic across multiple nodes, eliminating bottlenecks and achieving linear scalability for write-heavy workloads. This distributed write capability, combined with ScyllaDB’s high-performance architecture, positions it as a compelling solution for organizations seeking to maximize write throughput and system resilience.
Replica, read-only, and multi-master architectures play critical roles in shaping the scalability, availability, and performance of distributed databases. MongoDB, Cassandra, and ScyllaDB offer unique approaches to implementing these architectures, catering to diverse use cases and requirements. Whether it’s ensuring high availability with replica architectures, optimizing performance with read-only architectures, or empowering distributed writes with multi-master architectures, organizations can leverage these database technologies to achieve their scalability and resilience goals effectively.
Understanding NoSQL Databases: A Comparative Analysis of MongoDB, Cassandra, and ScyllaDB
NoSQL databases have revolutionized the way organizations handle data, offering flexible and scalable solutions to meet the demands of modern applications. MongoDB, Cassandra, and ScyllaDB stand out as leading NoSQL databases, each offering unique features and capabilities tailored to specific use cases. In this article, we delve into these databases, providing a comparative analysis of their strengths, weaknesses, and suitability for various applications.
Introduction to NoSQL Databases
NoSQL, or “Not Only SQL,” databases diverge from traditional relational databases by offering flexible data models, horizontal scalability, and high availability. These databases are designed to handle the challenges posed by massive volumes of unstructured or semi-structured data, making them ideal for modern web applications, real-time analytics, and IoT platforms.
MongoDB: The Document Store
MongoDB is a prominent document-oriented NoSQL database known for its flexibility and ease of use. It stores data in JSON-like documents, allowing developers to work with rich data structures without the constraints of a fixed schema. MongoDB’s flexible data model makes it well-suited for applications requiring rapid iteration and evolving data schemas.
Key features of MongoDB include:
- Flexible data model: MongoDB’s document-oriented approach enables developers to store and query complex, nested data structures.
- Rich query language: MongoDB supports a powerful query language with support for filtering, aggregation, and geospatial queries.
- Horizontal scalability: MongoDB can scale horizontally through sharding, distributing data across multiple nodes to handle high volumes of traffic and data.
MongoDB is commonly used in content management systems, e-commerce platforms, and real-time analytics applications where flexibility and scalability are paramount.
Cassandra: The Wide-Column Store
Cassandra is a distributed NoSQL database designed for high availability and linear scalability. It employs a decentralized architecture inspired by Google’s Bigtable, distributing data across a cluster of nodes for fault tolerance and resilience. Cassandra’s column-family data model allows for efficient storage and retrieval of wide rows, making it suitable for time-series data, IoT sensor data, and messaging systems.
Key features of Cassandra include:
- Distributed architecture: Cassandra replicates data across multiple nodes, ensuring fault tolerance and high availability.
- Tunable consistency: Cassandra allows developers to choose the consistency level for read and write operations, balancing performance and data consistency.
- Linear scalability: Cassandra scales linearly by adding or removing nodes to the cluster, making it suitable for large-scale deployments.
Cassandra is widely used in distributed systems, real-time analytics, and mission-critical applications requiring high availability and fault tolerance.
ScyllaDB: The High-Performance Database
ScyllaDB is a high-performance NoSQL database designed for maximum throughput and low latency. Built from the ground up in C++, ScyllaDB leverages advanced optimization techniques to achieve superior performance on modern hardware. Compatible with Apache Cassandra’s data model and API, ScyllaDB offers drop-in replacement capabilities with significantly improved performance.
Key features of ScyllaDB include:
- C++ architecture: ScyllaDB’s C++ architecture maximizes resource utilization and minimizes overhead, enabling it to achieve near-linear scalability.
- Compatibility with Cassandra: ScyllaDB is compatible with Cassandra’s data model and API, making it easy to migrate existing applications to ScyllaDB for improved performance.
- High throughput and low latency: ScyllaDB delivers industry-leading throughput and low latency, making it suitable for high-speed transactions, real-time analytics, and low-latency data processing.
ScyllaDB is commonly used in applications requiring maximum performance, such as financial services, ad tech, and online gaming platforms.
NoSQL databases offer flexible and scalable solutions for handling modern data challenges. MongoDB, Cassandra, and ScyllaDB represent three distinct approaches to NoSQL database design, each with its own strengths and use cases. Whether it’s MongoDB’s flexibility, Cassandra’s scalability, or ScyllaDB’s performance, organizations can choose the right NoSQL database to meet their specific requirements and achieve success in today’s data-driven world.
Examples of SQL statements for manipulating dates in each of the mentioned databases: MongoDB, Cassandra, and ScyllaDB.
MongoDB:
MongoDB uses the Aggregation Pipeline framework for advanced operations, including date manipulation.
db.collection.aggregate([
{
$project: {
// Extract year, month, and day from the date field
year: { $year: "$dateField" },
month: { $month: "$dateField" },
day: { $dayOfMonth: "$dateField" },
// Add or subtract days from the date field
newDate: { $add: ["$dateField", { $multiply: [1, 24, 60, 60, 1000] }] } // Add 1 day
}
}
])
Cassandra:
CQL (Cassandra Query Language) doesn’t have built-in date manipulation functions like traditional SQL. However, you can manipulate dates in your application code.
SELECT id, dateField FROM myTable WHERE dateField > '2022-01-01' AND dateField < '2022-01-31'; -- Example of date comparison
ScyllaDB:
ScyllaDB also relies on application-side manipulation for dates, as CQL lacks direct date manipulation functions.
SELECT id, dateField FROM myTable WHERE dateField > '2022-01-01' AND dateField < '2022-01-31'; -- Example of date comparison
In the provided SQL statements:
- MongoDB’s example demonstrates extracting year, month, and day from a date field, as well as adding or subtracting days from the date.
- Cassandra and ScyllaDB examples show basic date comparisons, but date manipulation would typically occur at the application level rather than in the database query due to the limitations of CQL.