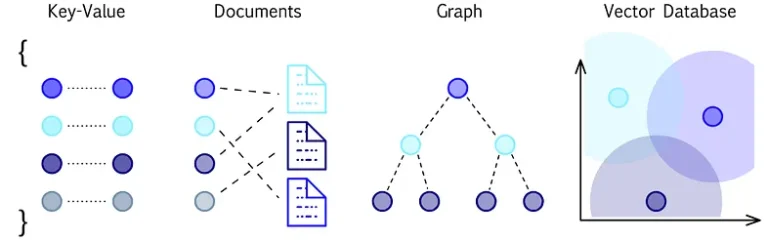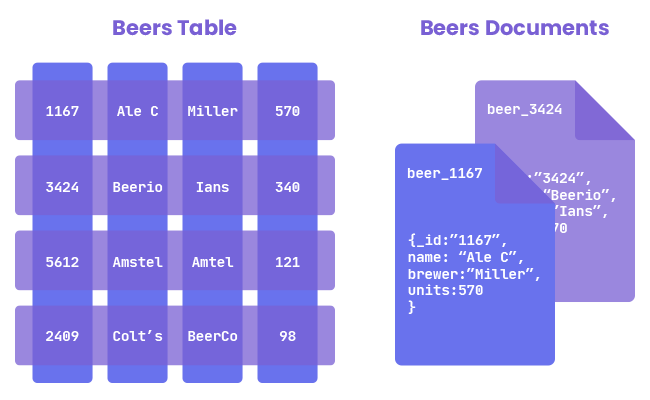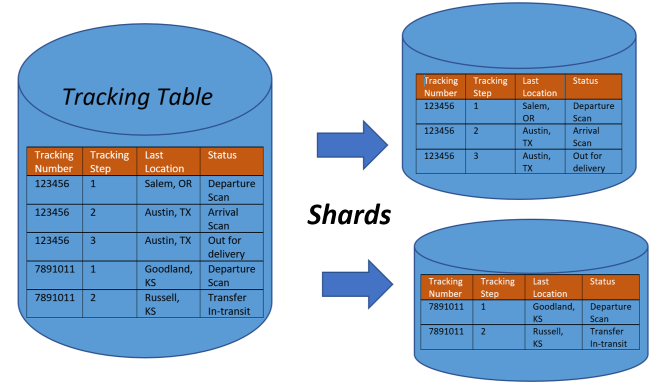
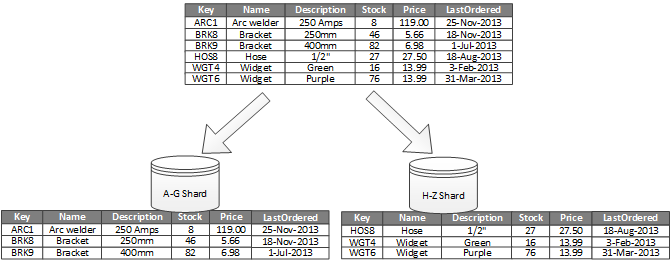
In the context of databases, a partition refers to the division of a database table or index into smaller, more manageable segments. These segments, known as partitions, allow for more efficient data storage, retrieval, and management. Partitioning is a technique commonly used in large-scale databases to improve performance, scalability, and manageability. Here are some key aspects of database partitioning:
Partition Key
A partition key is used to determine how data is distributed across partitions. It can be based on a specific column or set of columns in the table. The partition key should ideally distribute data evenly across partitions to ensure balanced load and efficient query processing.
Partitioning Methods
There are several methods for partitioning data in a database:
- Range Partitioning: Data is partitioned based on a specified range of values in the partition key. For example, you could partition a sales table based on the sales date, with each partition representing a specific time period (e.g., monthly or yearly).
- List Partitioning: Data is partitioned based on predefined lists of values in the partition key. For example, you could partition a customer table based on geographic regions, with each partition containing customers from a specific region.
- Hash Partitioning: Data is partitioned based on a hash function applied to the partition key. This method distributes data evenly across partitions without any predefined ranges or lists.
- Composite Partitioning: Data is partitioned using a combination of multiple partitioning methods. For example, you could first partition data by range and then further partition each range using hash partitioning.
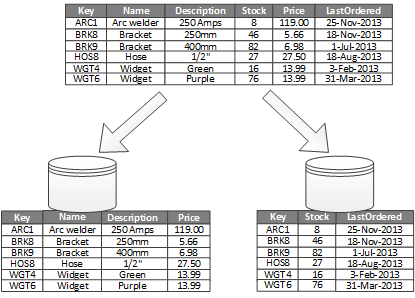
Benefits of Partitioning
- Improved Performance: Partitioning can improve query performance by reducing the amount of data that needs to be scanned or processed. Queries can be targeted to specific partitions, leading to faster response times.
- Scalability: Partitioning enables horizontal scalability by distributing data across multiple disks or servers. This allows databases to handle larger datasets and higher throughput.
- Manageability: Partitioning makes it easier to manage large tables by dividing them into smaller, more manageable chunks. Maintenance tasks such as backup, restore, and index rebuild can be performed on individual partitions rather than the entire table.
- Data Isolation: Partitioning can provide isolation between different sets of data, making it easier to manage access control and security policies for specific partitions.
Partitioning Considerations:
- Data Distribution: It’s important to choose a partitioning method and key that evenly distribute data across partitions to avoid hotspots and imbalance.
- Query Patterns: Partitioning should be aligned with the typical query patterns of the application to ensure that queries can benefit from partition pruning and efficient data retrieval.
- Maintenance Overhead: While partitioning can improve performance and manageability, it also adds complexity to database administration tasks such as partition maintenance and data movement.
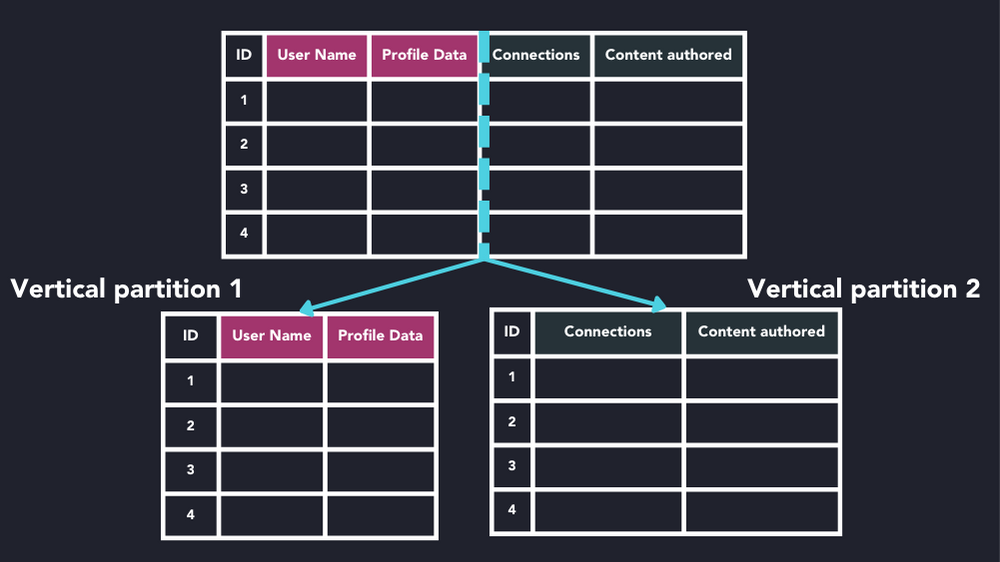

Overall, partitioning is a powerful technique used in database management to improve performance, scalability, and manageability of large-scale databases. By dividing tables or indexes into smaller partitions based on a partition key, databases can efficiently store, retrieve, and manage data, leading to better overall performance and user experience.