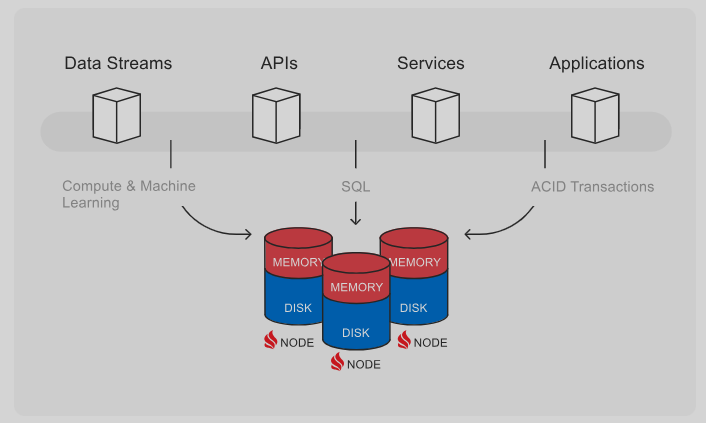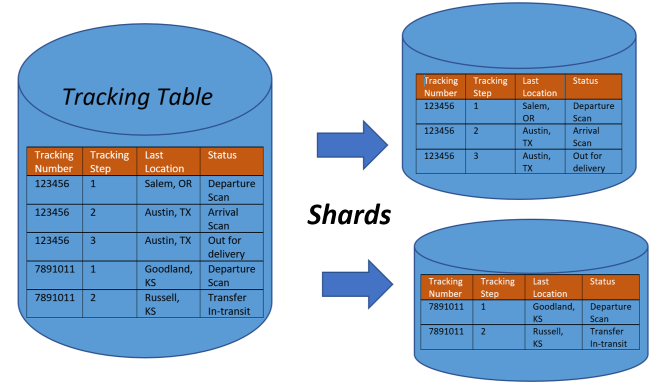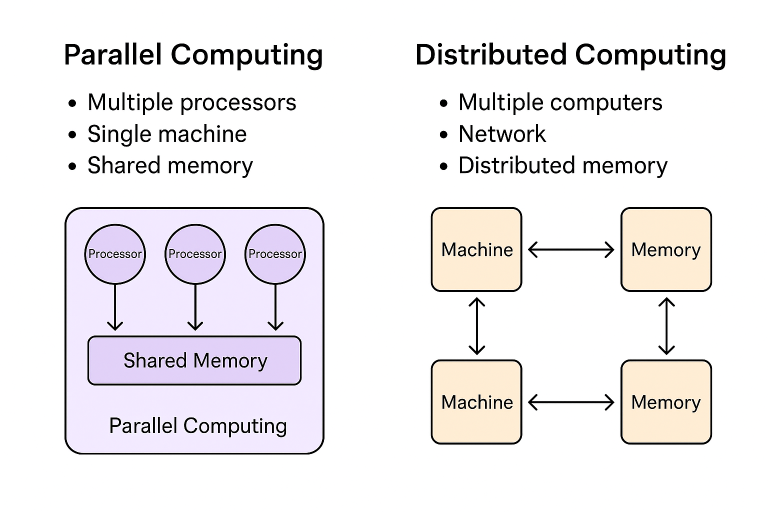
Introduction
In the world of database management systems, the choice between row-based and columnar databases is a crucial decision that significantly impacts performance, scalability, and analytical capabilities. In this article, we will delve into the realm of columnar databases, understanding their architecture, advantages, and implementation through sample code.
Understanding Columnar Databases:
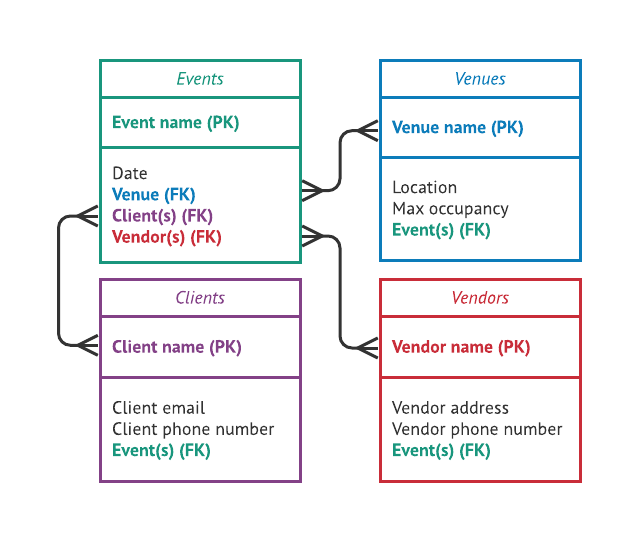
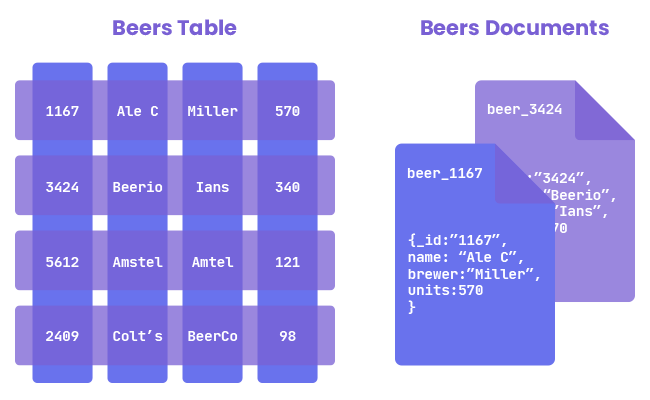
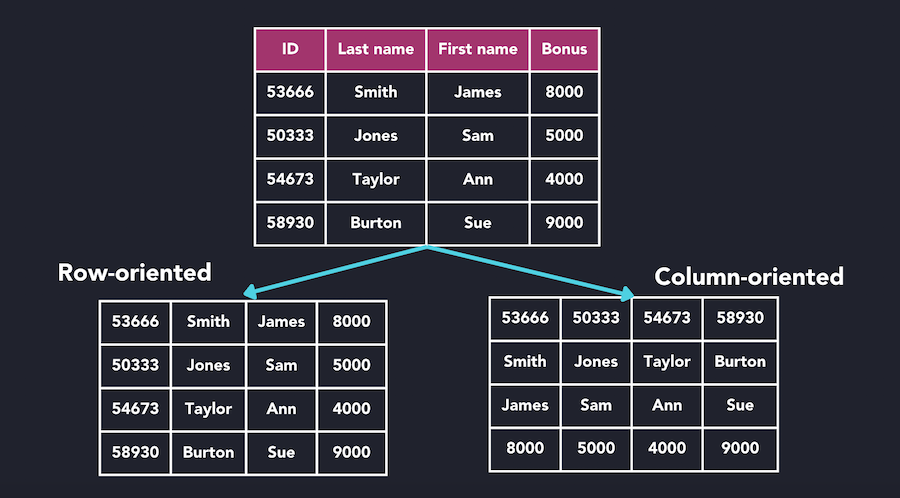
Traditional relational databases typically store data in rows, where each record contains all the fields associated with that record. On the other hand, columnar databases store data in columns, grouping values of the same attribute together. This structural difference leads to several advantages, especially in scenarios where analytical queries and aggregations are frequent.
Advantages of Columnar Databases:
- Improved Query Performance:
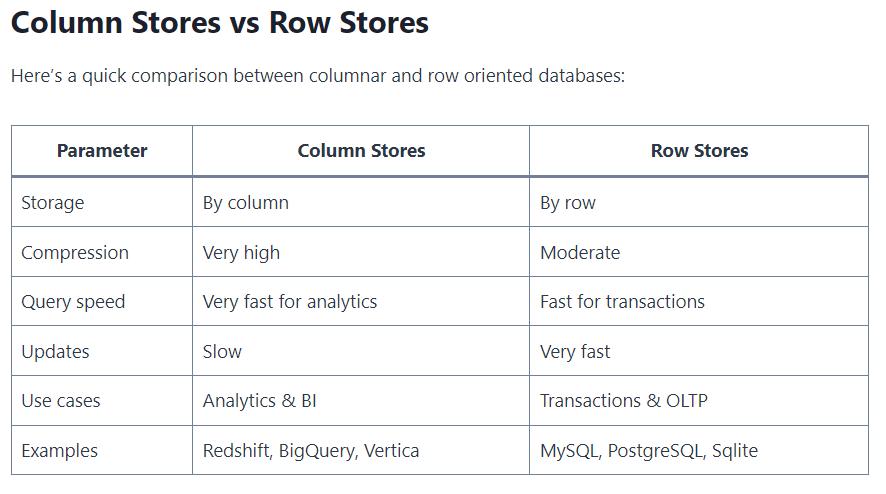
Columnar databases excel in analytical workloads, where queries often involve aggregations, filtering, and selecting specific columns. Since only the necessary columns are read during query execution, the data retrieval process is more efficient compared to row-based databases. - Compression and Storage Efficiency:
Columns with similar data types exhibit high compressibility, allowing for superior storage efficiency. This not only reduces storage costs but also enhances query performance as less data needs to be transferred from storage to memory. - Optimized for Analytics:
Columnar databases are well-suited for analytical processing, making them ideal for business intelligence and data warehousing applications. Aggregations and complex queries on large datasets become more manageable due to the columnar structure. - Parallel Processing:
The columnar architecture lends itself well to parallel processing, as operations can be performed independently on each column. This parallelism contributes to faster query execution and improved scalability.
Implementing a Columnar Database with Apache Cassandra:
Let’s explore the implementation of a simple columnar database using Apache Cassandra, a highly scalable and distributed NoSQL database.
- Installation:
Install Apache Cassandra by following the instructions on the official website (https://cassandra.apache.org/). - Creating a Keyspace and Table:
Use the Cassandra Query Language (CQL) to create a keyspace and table with columnar storage.
CREATE KEYSPACE mykeyspace WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1};
USE mykeyspace;
CREATE TABLE mytable (
id UUID PRIMARY KEY,
name TEXT,
age INT,
email TEXT
) WITH CLUSTERING ORDER BY (name ASC);
- Inserting Data:
Insert data into the columnar table.
INSERT INTO mytable (id, name, age, email) VALUES (uuid(), 'John Doe', 30, '[email protected]'); INSERT INTO mytable (id, name, age, email) VALUES (uuid(), 'Jane Smith', 25, '[email protected]');
- Querying Data:
Perform analytical queries on the columnar data.
SELECT name, age FROM mytable WHERE age > 25;
There are several open-source columnar databases available for use. Keep in mind that the landscape of open-source software may evolve, and new projects may emerge.
Here are some popular open-source columnar databases:
1. Apache Cassandra:
- Website: Apache Cassandra
- Description: While Cassandra is a NoSQL database, it has a column-family data model, making it suitable for handling large amounts of data with high write and read throughput.
2. ClickHouse:
- Website: ClickHouse
- Description: ClickHouse is an open-source columnar database management system developed by Yandex. It is designed for high-performance analytics on large datasets and supports real-time data processing.
3. MonetDB:
- Website: MonetDB
- Description: MonetDB is an open-source analytical database management system that uses a columnar storage approach. It is known for its high performance in analytical queries.
4. Apache HBase:
- Website: Apache HBase
- Description: While HBase is a distributed, scalable, and NoSQL database, it uses a columnar store and is often used for real-time read and write access to large datasets.
5. InfiniDB:
- Website: InfiniDB
- Description: InfiniDB is an open-source analytical database that uses a columnar storage engine. It is designed for high-performance queries on large datasets.
6. Druid:
- Website: Apache Druid
- Description: Druid is a real-time analytics database designed for sub-second query response times. It uses a columnar storage format and is well-suited for OLAP (Online Analytical Processing) workloads.
Please check the official websites and documentation for the most up-to-date information on these projects. Additionally, new open-source projects may have emerged since my last update. Always consider the specific requirements of your use case when choosing a database system.
Conclusion:
Columnar databases offer a compelling solution for organizations dealing with analytical workloads and large datasets. By understanding their advantages and implementing a simple example using Apache Cassandra, developers can harness the power of columnar databases for improved performance and scalability in data-intensive applications.